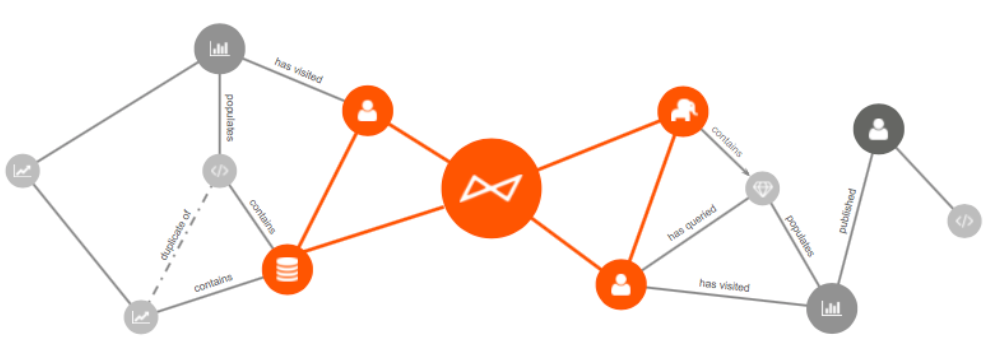
Within a plethora of organizations, finding and using the right data is a tedious and arduous process. Where, among the many databases in the organization, does the right table live? Is the data in the table up-to-date? Are people in the organization accessing the table? Which columns in the table should be used? Generally, analysts get the answers to these questions by relying on tribal knowledge; analysts need to tap on the shoulders of experts to get help, which can be irritating, lengthy, and sometimes, inconclusive.
To tackle this issue, Alation, a Silicon Valley based startup, launched a collaborative data catalog in 2012. A data catalog is an online repository that centralizes and curates all the data from multiple data storage sources, including databases, Hadoop structures, business intelligence/data visualization tools, documentation, conversations etc. It empowers analysts to self-serve and search as well as collaborate across diverse data sources in their organization. It facilitates the process of searching for data and understanding its context. Regarding Alation’s data catalog, the data curation is based on company usage, which means that the more Alation is used within the enterprise, the smarter it gets (through machine learning).
Data catalogs are relatively new in the big data space, and try to answer the needs of three types of data users:
- Data consumers (i.e data analysts): analyze and interpret data to synthesize large quantities of information
- Data curators (i.e data stewards, data governors): document and define data for quality control
- Data creators (i.e IT, DevOps, or a DBA administrator): ensure data accessibility and optimal utilization
Data catalogs have to be differentiated from data inventories. They curate data based on usage within the company. Data catalogs enable IT managers and data governors to understand how to effectively manage and govern the data while helping the business access the data they need.
