
While OpenAIs ChatGPT has found great popularity with the general public, companies have also been increasing the integration of OpenAI models into business applications. The use of Large Language Models (LLMs) offered by OpenAI provide great benefit to a variety of tasks, especially in the field of customer service, where LLMs help overcome limitations of current chatbots, like scripted responses or fixed decision trees. (Bilan, 2023) As I find myself developing business applications for a company using OpenAIs largue language models, I was surprised to learn that the GPT-3.5 and GPT-4 models seem to be getting worse over time according to some metrics (Chen, Zaharia, & Zou, 2023). Given these findings I would like to use this blog article to share my thoughts as well as those of experts on the issue.
For context, the research paper evaluated the performance of the March 2023 and the June 2023 model versions, by looking at seven different tasks including math problems, generating code and visual reasoning. The below shown excerpt of the results show that, differences in the March and June version can differ for GPT-4 and GPT-3.5 as seen by test e. Here GPT-4s performance increased significantly, while GPT-3.5s performance decreased.
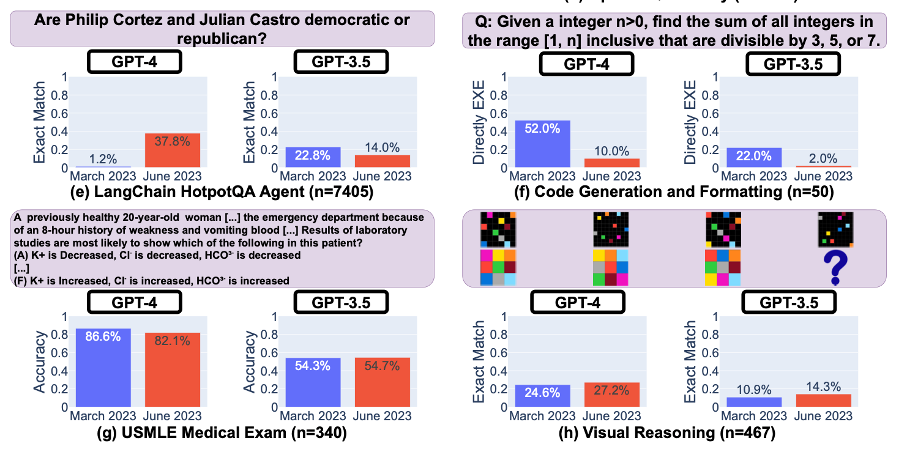
Through these findings over a relatively short period of time, a lack of transparency regarding model updates and their performance become evident. This lack of transparency can be a big issue for companies developing and operating business application with OpenAi’s models. For example, adopting and fine tuning a model for code generation in March of 2023 only to find the models performance to be not sufficient anymore in June of 2023. Even with continuous monitoring of the model’s quality, a feedback loop would need to exist to mitigate the effects of quality decline.
While the results do seem to have strong consequences for certain business applications, some experts critique the methodology used in the paper like the temperature setting when executing the prompt (Wilson, 2023) or the difference between capabilities and behavior of a LLM (Narayanan, & Kapoor, 2023). I personally believe that applications build using LLMs are not a build-it-and-forget-it tool. They must be constantly monitored for quality of output, which is to be defined per specific use case. Given the black box nature of LLMs this can be a challenging task. However, given the rapid releases of models within the last year, I believe more work will be done regarding stable models and quality control as well as a definition of certain performance metrics. I would appreciate your thoughts on the issue, where you aware of the degrading and do you think it has an effect on companies’ ability to implement LLMs into business applications?
Resources
Bilan, M. (2023, September 26). Statistics of ChatGPT & Generative AI in business: 2023 Report. Master of Code Global. https://masterofcode.com/blog/statistics-of-chatgpt-generative-ai-in-business-2023-report#:~:text=49%25%20of%20companies%20presently%20use,than%20%2475%2C000%20with%20the%20technology.
Chen, L., Zaharia, M., & Zou, J. (2023). How is ChatGPT’s behavior changing over time?. arXiv preprint arXiv:2307.09009
Narayanan, A., & Kapoor, S. (2023, July 19). Is GPT-4 getting worse over time? AI Snake Oil. https://www.aisnakeoil.com/p/is-gpt-4-getting-worse-over-time
Wilson, S., (2023, July, 19). https://twitter.com/simonw/status/1681733169182277632
