In the early 1990’s the WWW brought a revolution. 10 years later we witnessed the rise of the so-called Web 2.0, which brought us social media and e-commerce platforms. It transformed social interactions, bringing producers and consumers of information, goods and services closer together, as well as allowed us to enjoy P2P interactions on a global scale. Yet always with a middleman: a platform acting as a trusted intermediary between parties who did not know or trust each other. So, we began to socialise with each other and share information via centralised services provided by big corporations such as Google, Facebook, Microsoft and Amazon. It is indeed unsettling to realise how much these companies know about most of us. Also, it obviously makes it simpler for governments to carry out surveillance and impose censorship. Besides, should any of these centralised entities shut down, your data and contacts are gone. On the DWeb however, it would be harder for any government to block a site it doesn’t like, because the information can originate from other places instead.
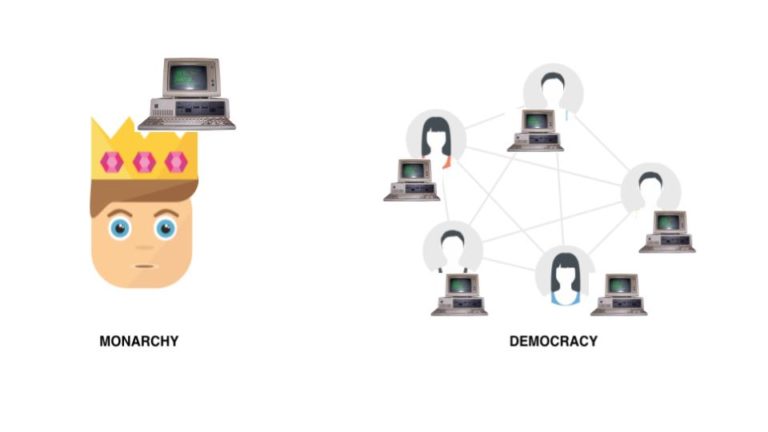
So, what is a decentralised web? The DWeb is about re-decentralising things – so we aren’t dependent on any intermediaries to connect us. Instead users maintain control of their data and connect and interact and send messages directly with others within their network. It is meant to be like the current web but without relying on centralised operators.
How is it different?
There are two core differences compared to the WWW. Firstly, there is a P2P connectivity, where your computer not only requests services but provides them, too (just like with the torrents). Secondly, DWeb protocols use links that identify information based on its content – what it is rather than where it is. This content-addressed approach makes it possible for websites and files to be stored and transmitted in various ways from computer to computer rather than always relying on a single server as the one channel for exchanging information.
How would our daily experience of using the Internet change? Either you won’t notice or it will be better. One aspect that is expected to change is that you will pay for content directly via cryptocurrencies because the business model of personalised advertising based on our data won’t work well in the DWeb.
What do you think of the DWeb? Is this a realistic future outlook?
Sources:
https://www.theguardian.com/technology/2018/sep/08/decentralisation-next-big-step-for-the-world-wide-web-dweb-data-internet-censorship-brewster-kahle
https://www.decentralizedweb.net/faq/
https://blockchainhub.net/web3-decentralized-web/