Data now plays a significant, if not crucial, role in how business, scientific research, and governance are carried out throughout the world. Although data can be of great benefit, it is crucial to mention that data does not come naturally. Data needs to be measured and actions in the real world need to be taken. In the real world, gathering data can be challenging and perhaps impossible. Additionally, privacy laws restrict access to important data. But what if there was a way to get around data constraints and enable the creation of enormous datasets? Technological advancements have made this possible, namely through the creation of synthetic data.
Synthetic data is artificially generated data, done by a computer. A model can be created of an actual dataset to infer new values in a synthetic dataset that are similar to the original values, thus creating similar distributions. Suppose, for instance, that 30% of participants in a real dataset reside in Amsterdam. This distribution can be used to generate artificial data, which generates fictitious values with the same distribution (30% of participants reside in Amsterdam). Huge datasets can be produced in this way, overcoming restrictions on data confidentiality and data gathering.

Data confidentiality
The usage of data containing distinctive and valuable microdata is constrained by data confidentiality restrictions (Nowok, Raab & Dibben, 2016). The limitations on confidentiality prevent this data from being used for two different reasons. The first is an increase in demand for user microdata (Rubin, 1993). The second is a proliferation of ethical and legal viewpoints on the repercussions of improperly disclosing confidential information (Rubin, 1993). To prevent the identity of data subjects, techniques like aggregation, recoding, record-swapping, suppressing sensitive information, and introducing random noise have been used (Nowok, Raab & Dibben, 2016). Ohm (2009) asserts that these techniques still fall short of totally preventing data exposure. Since synthetic data may mimic the original observed data and can maintain the relationships between variables, data privacy can be preserved by employing it. However, there are no revealing entries in the synthetic data (Nowok, Raab & Dibben, 2016). This indicates that by simulating the real dataset, synthetic datasets enable knowledge sharing without disclosing private information. Applications in the field of information science enable banking or medical data analysis without invading the client’s or patient’s privacy
Training ML algorithms
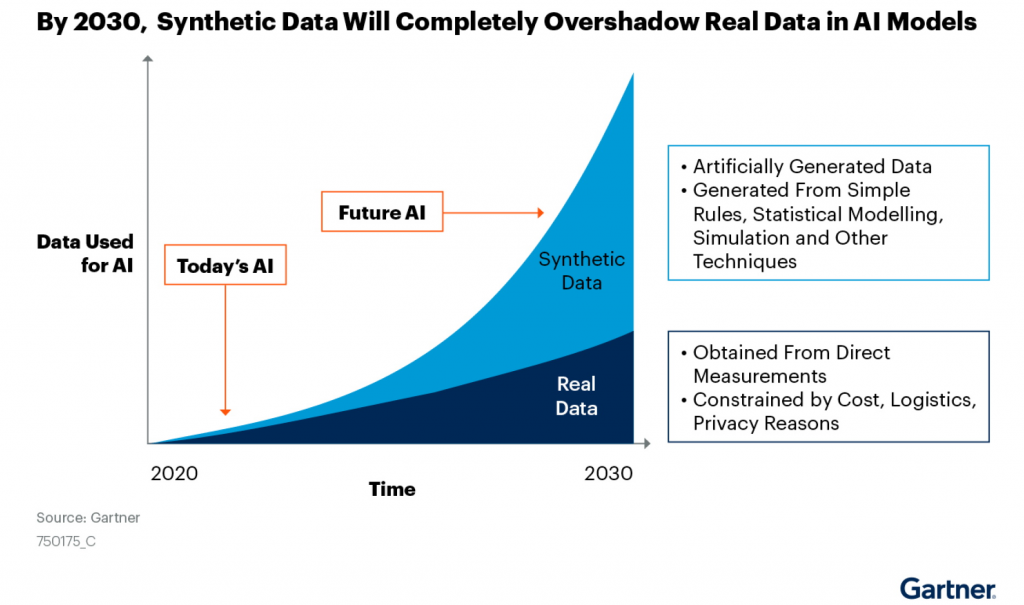
Data generation via synthetic data generators is affordable and scalable. The creation of synthetic data is frequently used in more contemporary applications, such as machine learning algorithms. Big models must be trained under supervision, which necessitates a large amount of labelled training data. It is expensive and time-consuming to manually gather this labelled training data (Gupta, Vedaldi & Zisserman, 2016). Tremblay et al. (2018) claim that synthetic datasets are a low-cost alternative to high-fidelity synthetic worlds or enormous volumes of hand-annotated real-world data for training neural networks. Both of which are frequent bottlenecks in machine learning systems. This indicates that the acquisition of data may be facilitated by synthetic datasets as it is possible to have a large amount of data without having to take actions in the real world to gather the data required to train such machine learning algorithms. It is convenient to be able to provide data from a variety of fictitious settings to the machine learning algorithms used to train, say, a self-driving automobile. It is simpler to generate synthetic data than it is to collect data from tens of thousands of real-world behaviors, let alone label it all. When it comes to classifying items in pictures, labeling is especially difficult. The figure below displays the potential that synthetic data has in training AI models.
Simulation models
Simulation models can be used to build artificial micropopulations in the context of applied research in order to forecast the results of policy intervention. The works of Smith, Clarke, and Harland (2009) as well as Barthelemy and Toint demonstrate this (2013). This means that researchers are able to create new (similar, but fictitious) instances of the data and can experiment with other variable configurations by employing synthetic data in the context of applied research. Finding the optimal result can help governance by experimenting with various variable setups. Dependencies between variables frequently need to be altered when experimenting with different variable combinations using real data. As a result, the dataset may behave differently or the researcher may need to collect additional data that focuses on a more narrow demographic that may not be relevant to the study.
Sources:
Barthelemy, J. and Toint, P. L. (2013). Synthetic Population Generation Without a Sample. [online]. Volume 47, issue 2. pp 131-294. Available at: https://doi.org/10.1287/trsc.1120.0408
Gupta, A., Vedaldi, A. and Zisserman, A. (2016). Synthetic Data for Text Localisation in Natural Images. [online] openaccess.thecvf.com. Available at: https://openaccess.thecvf.com/content_cvpr_2016/html/Gupta_Synthetic_Data_for_CVPR_2016_paper.html
Nowok, B., Raab, G.M. and Dibben, C. (2016). synthpop: Bespoke Creation of Synthetic Data in R. Journal of Statistical Software, [online] 74, pp.1–26. Available at: doi:10.18637/jss.v074.i11.
Ohm, P. (2009). Broken promises on privacy: responding to to the surprising failure of anonymization. Law journal library, [online]. pp.1701-1778. Available at: https://heinonline.org/HOL/Page?collection=journals&handle=hein.journals/uclalr57&id=1716&men_tab=srchresults
Rubin, D. B. (1993). Discussion, Statistical disclosure limitation. Journal of Official Statistics, [online] Vol 9. No. 2, pp461-468. Available at: https://www.scb.se/contentassets/ca21efb41fee47d293bbee5bf7be7fb3/discussion-statistical-disclosure-limitation2.pdf
Smith, D. M., Clarke, G. P., and Harland, K. (2009). Improving the Synthetic Data Generation Process in Spatial Microsimulation Models. Sage journals. [online] Volume 41, issue 5. Available at: https://doi.org/10.1068/a4147 Tremblay, J., Prakash, A., Acuna, D., Brophy, M., Jampani, V., Anil, C., To, T., Cameracci, E., Boochoon, S. and Birchfield, S. (2018). Training Deep Networks With Synthetic Data: Bridging the Reality Gap by Domain Randomization. [online] openaccess.thecvf.com. Available at: https://openaccess.thecvf.com/content_cvpr_2018_workshops/w14/html/Tremblay_Training_Deep_Networks_CVPR_2018_paper.html
